
🗣 Wd提问: 大数据分析源码定制
🤖 Ai回答:大数据分析源码定制概述
在当今数据驱动的时代,企业或组织需要从海量的数据中提取有价值的信息以支持决策。大数据分析是实现这一目标的核心技术手段之一,而 源码定制化开发 则能够根据具体业务需求灵活调整和优化解决方案。
本方案将围绕以下内容展开:
1、背景与意义
2、关键技术栈选择
3、功能模块设计
4、代码架构规划
5、实施步骤
一、背景与意义
随着互联网的普及和技术的发展,企业的运营过程中积累了大量结构化(如数据库记录)和非结构化的数据(如日志文件、文本、图像等)。这些数据蕴含着巨大的商业价值,但同时也带来了存储量大、处理复杂等问题。
通过自定义的大数据分析系统,可以针对特定场景进行深度挖掘:
提升效率:快速筛选出关键信息。
支持预测性维护:基于历史行为预判未来趋势。
助力精准营销:识别用户偏好并制定个性化策略。
实现智能化管理:自动化监控异常情况,并及时预警。
因此,在实际应用层面,一个可扩展且高度适配的企业级大数据平台显得尤为重要。
二、关键技术栈选择
为了构建高效稳定的大数据分析框架,我们需要结合当前主流技术和工具来搭建完整的生态系统。以下是推荐的关键组件及其作用说明:
1、数据采集层
Kafka: 高吞吐率的消息队列服务,用于实时收集来自不同来源的日志流或其他动态更新的内容;
bash
安装 Kafka 示例命令 (Linux)
wget https://downloads.apache.org/kafka/...
tar xzf kafka_*.tgz && cd kafka_*.*
bin/zookeeper-server-start.sh config/zookeeper.properties &
2、存储计算引擎
Hadoop HDFS: 分布式文件管理系统,适合大规模离线批处理任务的基础环境;
hadoop fs -mkdir /data/raw_logs/
hdfs dfsadmin ...
Apache Spark: 快速高效的分布式内存运算库,适用于交互查询及机器学习模型训练等工作负载类型:
python
from pyspark.sql import *
spark = SparkSession.builder \
.appName(CustomBigDataAnalysis)\
...getOrCreate()
df=spark.read.csv(/path/to/data)
或者使用 PySpark 来简化 Python 开发流程:
pyton
from pyspark.ml.feature import VectorAssembler, StandardScaler
构建特征向量化器
assembler = VectorAssembler(inputCols=[feature_a, feature_b], outputCol=features)
3、流式处理能力增强
*Flink*: 如果项目涉及持续不断流入的新鲜事件,则 Flink 是一种理想的选项——它提供了低延迟响应机制以及精确一次语义保证特性.
注意事项: 根据实际情况决定是否引入其他补充型产品比如 Druid 等作为辅助加速 OLAP 查询性能.
4、可视化进程追踪 & 用户界面展示
*Grafana + Prometheus:* 连接后端逻辑输出结果到前端仪表盘上直观呈现统计图表帮助管理者理解整体运行状况;
或者采用更高级别的 BI 工具例如 Tableau , PowerBI 直连至最终生成报表供进一步解读.
总结来说整个生态链大致如下图所示 :
| 层次 | 组件 |
| 输入管道 | Apache Kafka |
| 基础设施 | Hadoop/HDFS |
| 计算核心 | Apache Spark/Flink/Presto/Snowflake(云原生) |
当然也可以依据预算限制选用开源版本或是付费订阅形式的服务商提供的托管套餐 .
三 : 模块划分
接下来我们按照职责范围拆解为若干独立子单元便于后续分工协作完成各自部分的功能点 。主要包括以下几个方面:
A ) 日常运维监测
主要负责对集群健康状态进行全面检查确保资源利用率合理分配同时避免潜在故障发生影响正常运作。
示例脚本片段 :
shell script
!/bin/bash
check_hive_metastore(){
echo [INFO] Checking Hive Metastore Status...
if ! nc -vzw $METASTORE_HOST:$PORT; then exit_with_error $? $HOSTNAME hive metastore is down!
fi}
main() {
check_hive_metastore }
main true ;
exit ${?};
此外还可以借助 Nagios/Zabbix 类似于第三方插件定期扫描各项指标变化以便提前发现问题根源所在.
B.) ETL流水线整合
ETL即Extract Transform Load过程描述了如何把原始格式转换成标准化后的可用形态再加载进目的位置的过程 .
这里涉及到清洗规则设定字段映射关系建立等等操作细节都需要事先明确下来才能顺利执行下去 .
C.)、特定领域算法集成
如果应用场景偏向金融风控信贷审批等领域的话可能还需要额外添加一些复杂的数学公式推导或者是神经网络之类的AI相关技能进来配合解决难题 ; 而对于零售行业而言则更多关注客户画像刻画之类的问题即可满足日常所需条件要求啦~ !
D)、投入产出比评估体系建构
最后一步就是衡量投入成本跟预期收益之间的比例大小从而判断此次投资到底值不值得继续坚持做下去呀 ? 当然这中间肯定少不了各种对比实验的设计安排还有后期跟踪反馈环节的支持才行哦~
四 :编码规范建议书稿模板样式统一标准文档整理汇编工作计划表制作等相关事宜也都是必不可少的重要组成部分哟! 不过由于篇幅有限无法一一列举出来所以就先到这里为止咯希望大家都能从中获得启发找到适合自己发展的方向吧谢谢观看再见喽拜了个遍~~ ~ 😊😊😊
📣 商家广告:

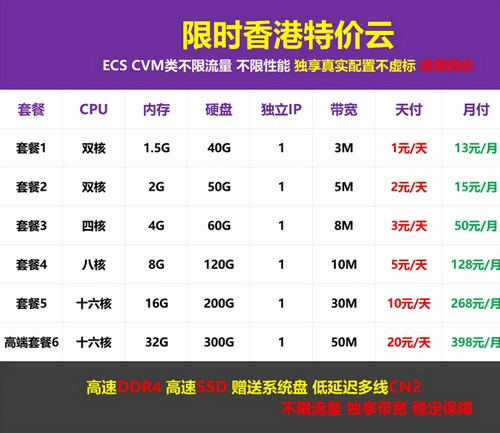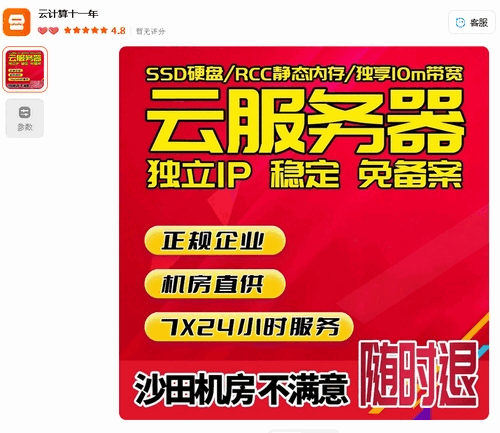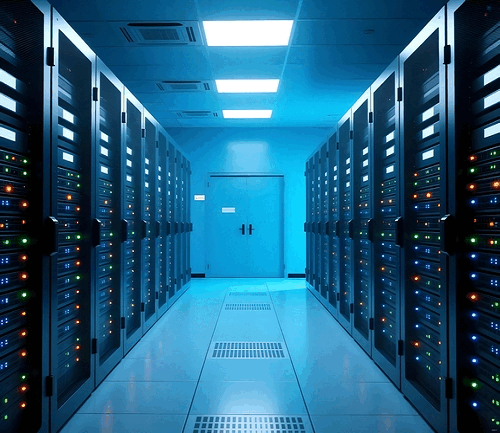



0
IP地址: 134.8.153.231
搜索次数: 0
提问时间: 2025-11-05 20:54:28
🛒 域名购买:
363.net.cn
z.gz.cn
02.gs
n-f.cn
m.tj.cn
25.gs
61.gs
3.gx.cn
81.biz
990.net.cn
❓️ 热门提问:
部队屏蔽机房建设标准
东莞网站开发
vps和独立服务器
php环境快照
广东机房建设
专业网店托管代运营
宁夏idc机房
云手机服务
vps服务器架设
网站推广长尾关键词
豌豆Ai站群搜索引擎系统
🌐 域名评估:
shopcarpetny.com
e-d.cn
i.qh.cn
trump.bj.cn
pjku.cn
goih.cn
pp.ln.cn
sawebu.com
le.nm.cn
dd.ha.cn
⛏ 最新挖掘:
凯里酸汤鱼
贵阳烤脑花
都匀毛尖茶
花溪牛肉粉
贵阳烤生蚝
贵阳烤豆腐
贵阳纸包鱼
贵阳特色菜


🤝 关于我们:
豌豆Ai
域名
建站
站群
留痕
推广
评估
源码
开发Ai
工具
日记
价格
加盟
广告
流量
留言
联系

📢 温馨提示:本站所有问答由Ai自动创作,内容仅供参考,若有误差请用“联系”里面信息通知我们人工修改或删除。
👉 技术支持:本站由豌豆Ai提供技术支持,使用的最新版:《豌豆Ai站群搜索引擎系统 V.25.10.25》搭建本站。