
🗣 Wd提问: 蜘蛛池程序PHP版
🤖 Ai回答:蜘蛛池(Spider Pool)是一种用于爬虫系统的架构设计,通常用于分布式爬虫任务的管理和调度。它可以帮助你管理多个爬虫节点,分配任务,并收集爬取的数据。PHP版的蜘蛛池程序可以通过编写代码来实现这些功能。
以下是一个简单的PHP版蜘蛛池程序的示例,展示如何实现一个基本的分布式爬虫系统。这个示例包括以下几个部分:
1、任务管理:存储和分配爬取任务。
2、爬虫节点:模拟多个爬虫节点从任务队列中获取任务并执行爬取。
3、数据收集:将爬取的数据收集并存储。
1、环境准备
确保你的服务器上已经安装了以下软件:
PHP 7.x 或更高版本
MySQL 数据库(用于存储任务和数据)
Apache 或 Nginx(作为Web服务器)
2、数据库设计
创建一个MySQL数据库,用于存储任务和爬取的数据。以下是两个表的结构:
`tasks` 表(存储待爬取的任务)
sql
CREATE TABLE tasks (
id INT AUTO_INCREMENT PRIMARY KEY,
url VARCHAR(255) NOT NULL,
status ENUM('pending', 'in_progress', 'completed') DEFAULT 'pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
`crawled_data` 表(存储爬取的数据)
sql
CREATE TABLE crawled_data (
id INT AUTO_INCREMENT PRIMARY KEY,
url VARCHAR(255) NOT NULL,
content TEXT,
crawled_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
3、PHP代码实现
3.1 初始化任务(任务管理)
创建一个PHP脚本 `init_tasks.php`,用于初始化一些待爬取的任务。
php
<?php
// 数据库连接配置
$host = 'localhost';
$dbname = 'spider_pool';
$username = 'root';
$password = '';
try {
$pdo = new PDO(mysql:host=$host;dbname=$dbname, $username, $password);
$pdo-setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
// 初始化任务
$urls = [
'https://65.hk/page1',
'https://65.hk/page2',
'https://65.hk/page3'
];
foreach ($urls as $url) {
$stmt = $pdo-prepare(INSERT INTO tasks (url) VALUES (:url));
$stmt-execute(['url' = $url]);
}
echo 任务初始化完成!;
} catch (PDOException $e) {
echo 数据库连接失败: 、$e-getMessage();
}
?
3.2 爬虫节点(任务分配与爬取)
创建一个PHP脚本 `crawler_node.php`,模拟多个爬虫节点从任务队列中获取任务并执行爬取。
php
<?php
// 数据库连接配置
$host = 'localhost';
$dbname = 'spider_pool';
$username = 'root';
$password = '';
try {
$pdo = new PDO(mysql:host=$host;dbname=$dbname, $username, $password);
$pdo-setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
// 获取一个待处理的任务
$stmt = $pdo-prepare(SELECT * FROM tasks WHERE status = 'pending' LIMIT 1 FOR UPDATE);
$stmt-execute();
$task = $stmt-fetch(PDO::FETCH_ASSOC);
if ($task) {
// 更新任务状态为进行中
$updateStmt = $pdo-prepare(UPDATE tasks SET status = 'in_progress' WHERE id = :id);
$updateStmt-execute(['id' = $task['id']]);
// 模拟爬取内容
$url = $task['url'];
$content = file_get_contents($url); // 实际应用中可以使用 CURL 或其他爬虫库
// 存储爬取的数据
$insertStmt = $pdo-prepare(INSERT INTO crawled_data (url, content) VALUES (:url, :content));
$insertStmt-execute(['url' = $url, 'content' = $content]);
// 更新任务状态为已完成
$updateStmt = $pdo-prepare(UPDATE tasks SET status = 'completed' WHERE id = :id);
$updateStmt-execute(['id' = $task['id']]);
echo 任务 {$task['id']} 已完成,URL: {$url}\n;
} else {
echo 没有待处理的任务。\n;
}
} catch (PDOException $e) {
echo 数据库操作失败: 、$e-getMessage();
}
?
3.3 定时任务(模拟多个爬虫节点并发运行)
你可以使用 `cron` 定时任务来模拟多个爬虫节点并发运行。例如,每分钟运行一次 `crawler_node.php` 脚本。
在 Linux 系统中,编辑 crontab 文件:
bash
crontab -e
添加以下行:
bash
* * * * * php /path/to/crawler_node.php
这将每分钟运行一次 `crawler_node.php`,模拟多个爬虫节点并发处理任务。
4、数据展示(可选)
你可以创建一个简单的网页来展示爬取的数据。例如,创建一个 `view_data.php` 文件:
php
<?php
// 数据库连接配置
$host = 'localhost';
$dbname = 'spider_pool';
$username = 'root';
$password = '';
try {
$pdo = new PDO(mysql:host=$host;dbname=$dbname, $username, $password);
$pdo-setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
// 查询已爬取的数据
$stmt = $pdo-query(SELECT * FROM crawled_data ORDER BY crawled_at DESC);
$data = $stmt-fetchAll(PDO::FETCH_ASSOC);
if ($data) {
echo <h2已爬取的数据</h2;
echo <ul;
foreach ($data as $item) {
echo <li<strongURL:</strong {$item['url']} <br<strong内容:</strong 、substr($item['content'], 0, 200) 、..、<br<strong爬取时间:</strong {$item['crawled_at']}</li;
}
echo </ul;
} else {
echo 暂无爬取数据。;
}
} catch (PDOException $e) {
echo 数据库操作失败: 、$e-getMessage();
}
?
5、总结
以上是一个简单的PHP版蜘蛛池程序的实现示例。它包括任务管理、爬虫节点、数据收集等功能。实际应用中,你可能需要考虑以下优化和扩展:
分布式任务分配:使用消息队列(如 RabbitMQ、Kafka)来实现更高效的分布式任务分配。
错误处理:增加对网络请求失败、超时等情况的处理。
反爬虫机制:模拟用户代理、IP代理等,避免被目标网站封禁。
数据存储优化:使用 Redis、Elasticsearch 等工具来存储和查询爬取的数据。
监控与日志:记录爬虫的运行状态和错误日志,便于调试和维护。
希望这个示例能帮助你理解如何用PHP实现一个简单的蜘蛛池程序!如果你有更多问题,欢迎继续提问。
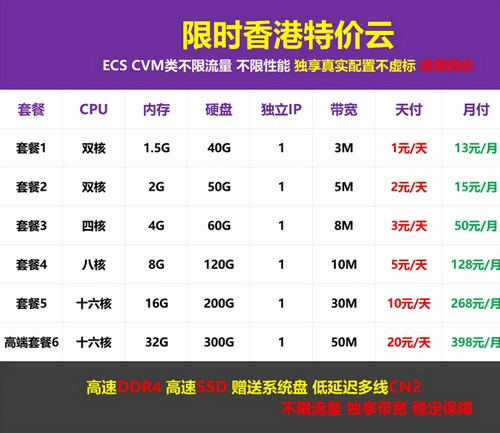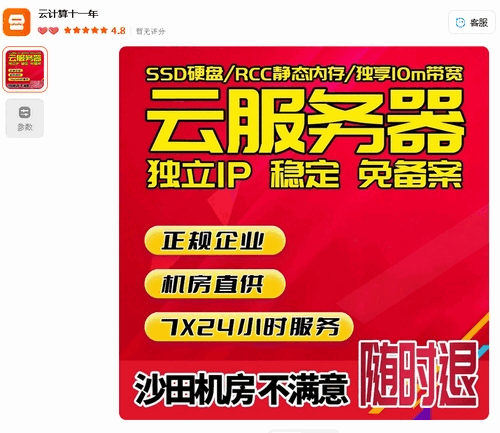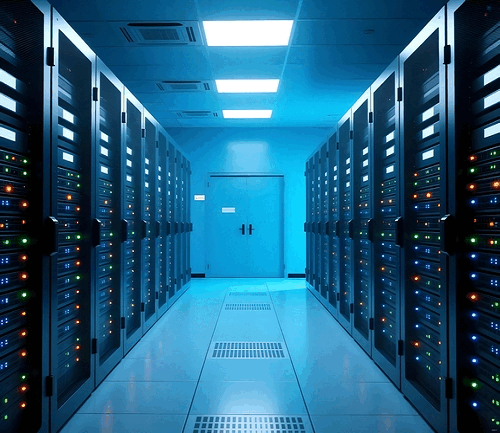
📣 商家广告:




0
IP地址: 104.44.167.191
搜索次数: 7
提问时间: 2025-12-28 12:06:54
域名购买
热门提问
域名评估
最新挖掘
热门作画


关于我们
加入群聊



友情链接